数据库学习笔记 | MySQL
唠唠闲话
数据库是“按照数据结构来组织、存储和管理数据的仓库”,是一个长期存储在计算机内的、有组织的、可共享的、统一管理的大量数据的集合。
参考 B 站:MySQL 数据库从入门到精通
软件安装
Ubuntu 系统
安装参考:How To Install MySQL on Ubuntu 20.04,以及这里
-
更新软件列表
1
sudo apt update
-
安装
mysql-server1
2sudo apt install mysql-server -y
sudo apt install mysql-client -y # 链接远程客户端注:如果只是想通过
mysql连接服务器,而不是在本地创建数据库,可以只执行第二条命令,安装客户端 -
按提示设置密码,用
tab选择确认
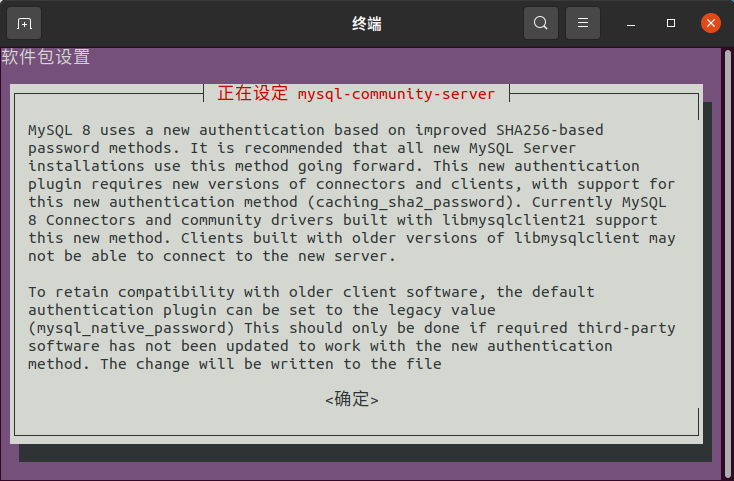
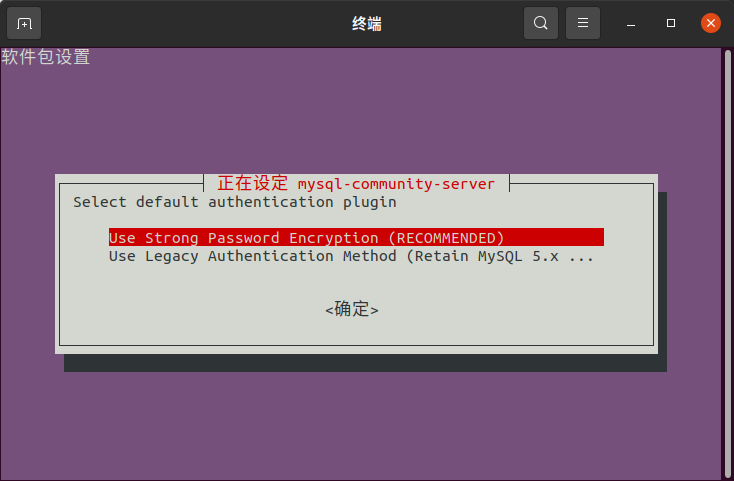
之后弹出安全配置,按默认即可
-
查看
mysql版本以及确认mysql服务正在运行1
2
3mysql --version
# mysql Ver 8.0.29 for Linux on x86_64 (MySQL Community Server - GPL)
sudo systemctl status mysql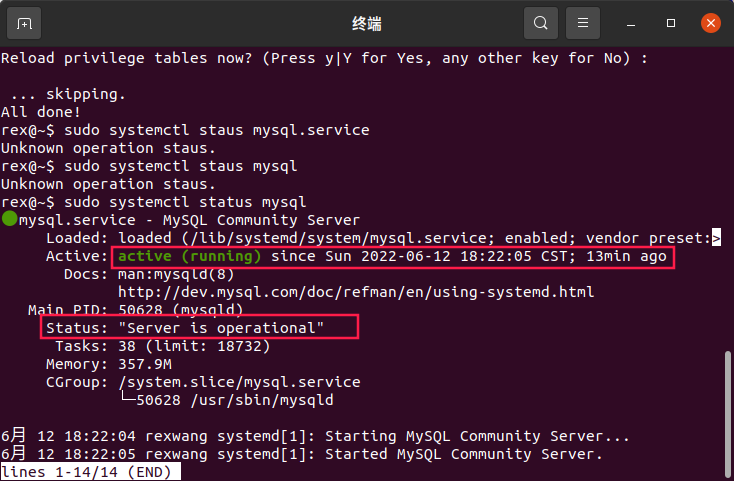
-
输入以下命令,配置
MySQL,并按提示输入前边设置的密码1
sudo mysql_secure_installation
一路按
回车选择默认配置即可 -
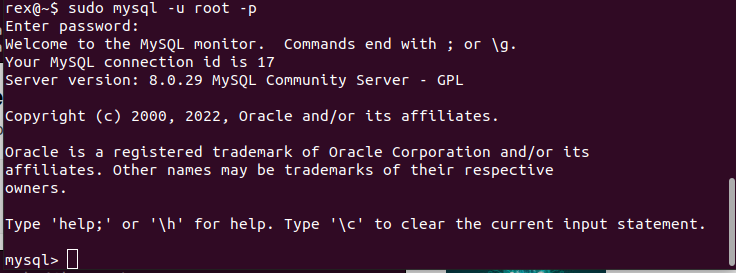
输入
sudo mysql -u -root -p登录 MySQL 服务,其中-u指定用户为 root,-p指定用密码登录
Win 系统
占位
软件重装
完全删除
1 | sudo -i |
概述
-
数据库相关概念:
名称 全称 英文全称 数据库 存储数据的仓库,有组织的存储 DataBase 数据库管理系统 操纵和管理数据库的大型软件 DataBase Management System(DBMS) 结构化查询语言 操作关系型数据库的编程语言标准 Structured Query Language(SQL) -
关系型数据库:建立在关系模型上,有多张相互连接的二维表组成的数据库
-
主流的关系型数据库管理系统
- Oracle
- MySQL(博客重点)
- 等等
简单说:用户通过 SQL 语言操控数据库管理系统,进而操纵数据库的创建,内部表格的创建修改等等。
SQL 通用语法
-
基本语法
- 单行或多行书写,分号作为语句结尾
- 使用
--单行注释,/* */多行注释 - 在 MySQL 中,可以使用
#单行注释 - SQL 中的命令不区分大小写
-
SQL 分类
| 分类 | 全称 | 说明 |
| — | — | ---- |
| DDL | Data Definition Language | 数据定义语言,用来定义数据库的对象(数据库,表,字段)
| DML | Data Manipulation Language | 数据操作语言,用来对数据库表中的数据增删改
| DQL | Data Query Language | 数据查询语言,用来查询数据库中表的记录
| DCL | Data Control Language | 数据控制语言,用来创建数据库用户,控制数据库访问权限等
DDL-数据定义语言
用于操作数据库的对象,包括数据库,表,字段等。
数据库操作
-
创建数据库
1
2
3# 基础语法
# create database [if not exists] <database_name>;
create database rextest;
-
查询所有数据库
1
SHOW DATABASES;
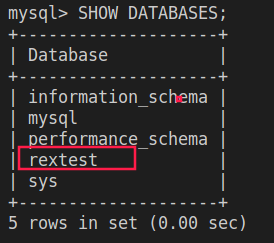
-
删除数据库
1
2
3# 基础语法
# drop database [if exists] <database_name>;
drop database rextest;
-
切换到数据库
1
2
3# 基础语法
# use <database_name>;
use rextest; # create database rextest;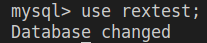
-
查询当前数据库
1
select database();
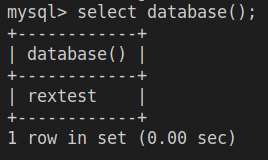
表操作
-
创建表
1
2
3
4
5
6
7
8
9
10
11# 基础语法
# create table <表名> (
# <字段1(列名)> <字段1 类型> [comment '字段1 注释'],
# <字段2(列名)> <字段2 类型> [comment '字段2 注释'],
# ) [comment '表注释'];
create table tb_user (
id int comment '用户id',
name varchar(20) comment '用户名',
age int comment '用户年龄',
gender varchar(1) comment '性别'
) comment '用户表'; -
表查询
1
2
3
4
5
6
7
8# 查询当前数据库的所有表
show tables;
# 查询表结构
# desc <table_name>
desc tb_user;
# 查询建表语句
# show create table <table_name>
show create table tb_user;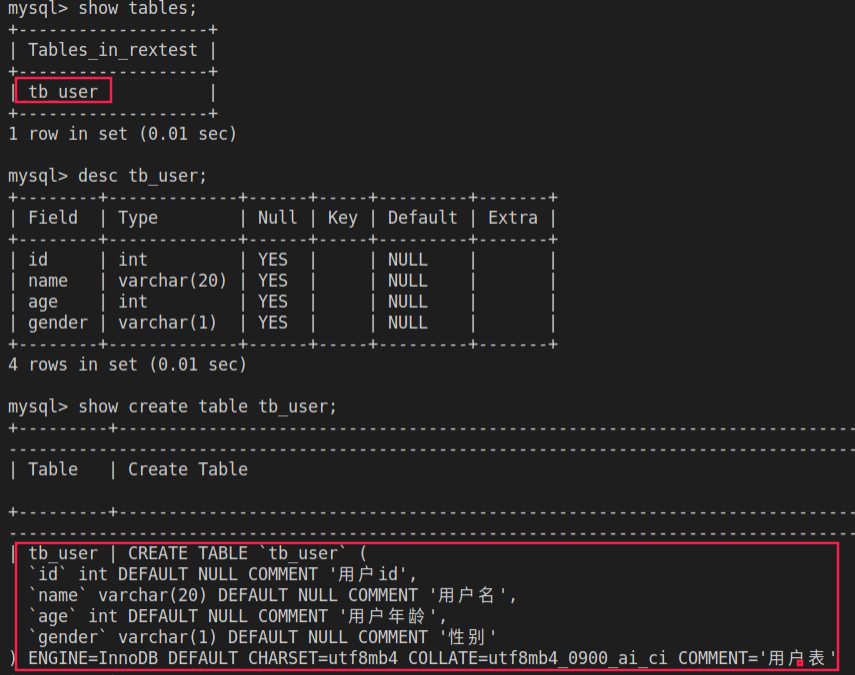
-
数值类型(不区分大小写)
类型 大小(byte) 有符号范围 无符号范围 tinyint 1 -128 ~ 127 0 ~ 255 smallint 2 -32768 ~ 32767 int/integer 4 -2^31 ~ 2^31-1 0 ~ 2^32-1 bigint 8 -2^63 ~ 2^63-1 0 ~ 2^64-1 float 4 -3.402823466E+38 ~ 3.402823466E+38 double 8 -1.7976931348623157E+308 ~ 1.7976931348623157E+308 decimal varying -
字符串类型(不区分大小写)
类型 大小(byte) 描述 char 0 ~ 255 定长字符串 varchar 0 ~ 65535 边长字符串 tinytext 0 ~ 255 短文本字符串 text 0 ~ 65535 长文本字符串 mediumtext 0 ~ 16777215 中等长度文本字符串 longtext 0 ~ 4294967295 极大文本字符串 此外还有
blob等二进制类型数据,但较少用到。
补充示例1
2
3
4
5
6create table tb_user (
id int comment '用户id',
name varchar(20) comment '用户名', # 边长字符串
age tinyint unsigned comment '用户年龄', # 无符号小整数
gender char(1) comment '性别' # 定长字符串
) comment '用户表'; -
添加字段
1
2
3# alter table <表名> add <字段名> <类型> [comment '注释']
alter table tb_user add nickname varchar(20) comment '昵称';
desc tb_user;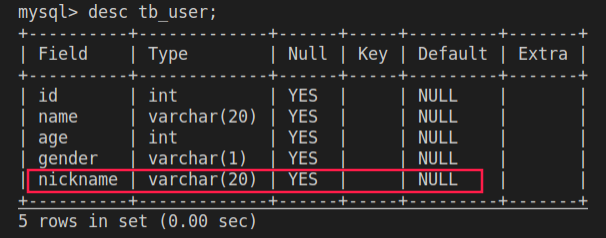
-
修改字段
1
2
3# 修改数据类型
# alter table <表名> modify <字段名> <新类型> [comment '注释']
alter table tb_user modify age int unsigned comment '用户年龄';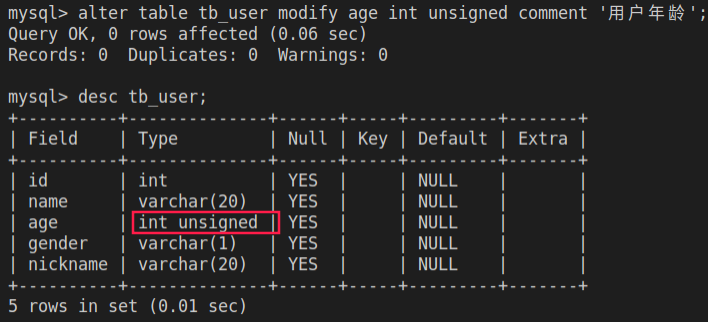
1
2
3
4# 修改字段名和字段类型
# alter table <表名> change <旧字段名> <新字段名> <新类型> [comment '注释']
alter table tb_user change gender gender char(1) comment '用户年龄';
desc tb_user;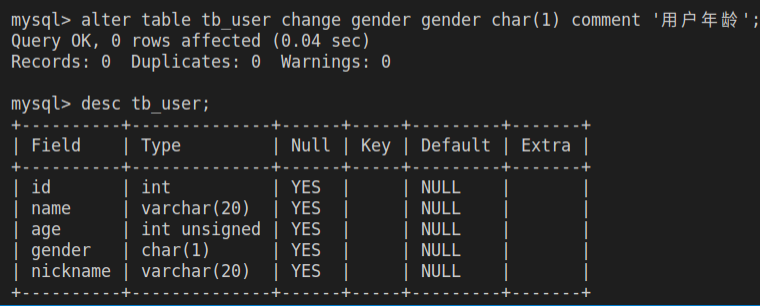
-
删除字段
1
2
3# alter table <表名> drop <字段名>
alter table tb_user drop nickname;
desc tb_user;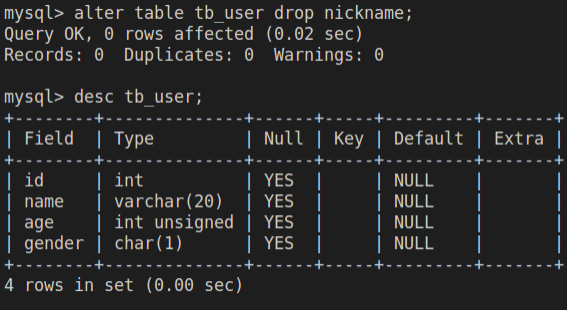
-
修改表名
1
2
3# alter table <表名> rename to <新表名>
alter table tb_user rename to tb_user_new;
show tables;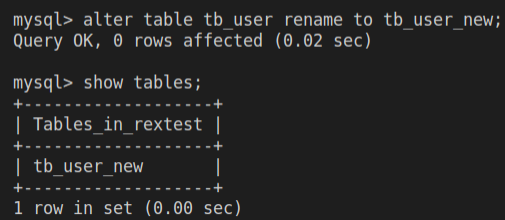
-
复制表
1
2
3
4
5# create table <新表名> like <旧表名>
create table tb_user_cp like tb_user_new;
# 等价写法
creat table tb_user_cp select * from tb_user_new;
show tables;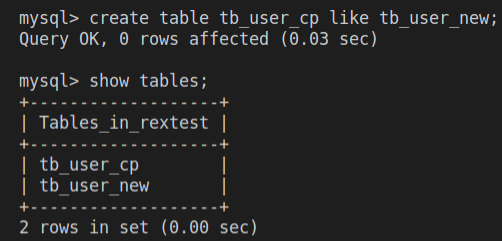
-
删除表
1
2
3
4
5# 删除整个表格
# drop table [if exists] <表名>
drop table tb_user_cp;
# 删除表格并重新创建
# truncate table [if exists] <表名>
总结
-
数据库操作
1
2
3
4
5
6
7
8
9
10# 创建数据库
create database [if not exists] <database_name>;
# 查询数据库
show databases;
# 删除数据库
drop database <database_name>;
# 切换数据库
use <database_name>;
# 查询当前数据库
select database(); -
表内操作
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20-- 创建表
create table <表名> (
<字段名> <类型> [comment '注释']
[, ...]
) [comment '注释'];
-- 查询表
show tables;
-- 查询表结构
desc <表名>;
-- 查询建表语句
show create table <表名>;
-- 添加字段
alter table <表名> add <字段名> <类型> [comment '注释'];
-- 修改字段
--- 修改数据类型
alter table <表名> modify <字段名> <新类型> [comment '注释'];
--- 修改字段名和字段类型
alter table <表名> change <旧字段名> <新字段名> <新类型> [comment '注释'];
-- 删除字段
alter table <表名> drop <字段名>; -
表操作
1
2
3
4
5
6
7
8
9-- 修改表名
alter table <表名> rename to <新表名>;
-- 复制表
create table <新表名> like <旧表名>;
create table <新表名> select * from <旧表名>;
-- 删除表
drop table [if exists] <表名>;
-- 删除表格并重新创建
truncate table [if exists] <表名>;
图形化工具
软件安装-Ubuntu
-
下载 DataGrip2022-02安装包 以及激活码文件,将安装包解压到需要安装的目录,比如
/opt/DataGrip/ -
解压后的文件结构
1
2
3
4
5
6
7
8
9
10# tree /opt/DataGrip/ -L 1
/opt/DataGrip/
├── bin
├── build.txt
├── Install-Linux-tar.txt
├── jbr
├── lib
├── license
├── plugins
└── product-info.jsonInstall-Linux-tar.txt为软件的安装说明 -
运行
bin目录下的datagrip.sh运行软件1
2cd /opt/DataGrip/
bash ./bin/datagrip.sh执行脚本后,会提示激活软件
-
解压激活文件,查看目录结构
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20├── Activation Codes
│ ├── AppCode.txt
│ ├── CLion.txt
│ ├── DataGrip.txt
│ ├── GoLand.txt
│ ├── IntelliJ IDEA.txt
│ ├── PhpStorm.txt
│ ├── PyCharm.txt
│ ├── Rider.txt
│ ├── RubyMine.txt
│ └── WebStorm.txt
├── ja-netfilter-all
│ ├── config-jetbrains
│ ├── ja-netfilter.jar
│ ├── plugins-jetbrains
│ ├── README.pdf
│ ├── scripts
│ ├── sha1sum.txt
│ └── vmoptions
└── Readme.txt -
打开
DataGrip.txt,将激活码复制到软件窗口,成功激活后的页面显示如下
-
如果激活码失效,则运行激活文件下的
scripts/install.sh脚本进行安装 -
设置环境变量,简单起见,编写启动脚本
1
2
3touch ~/.local/bin/datagrip ## 创建脚本文件
chmod a+x ~/.local/bin/datagrip ## 添加执行权限
vi ~/.local/bin/datagrip ## 编辑脚本文件脚本内容如下:
1
2
bash /opt/DataGrip/bin/datagrip
软件安装-Windows
占位,待定
DML-数据操作语言
用来对数据库表中的数据增删改,主要有三类语句:
-
添加数据:INSERT
-
修改数据:UPDATE
-
删除数据:DELETE
-
添加数据
1
2
3
4
5
6
7
8# 给指定字段添加数据
insert into <表名> (<字段名1>, <字段名2>, ...) values (<值1>, <值2>, ...);
# 批量添加数据
insert into <表名> (<字段名1>, <字段名2>, ...) values (<值1>, <值2>, ...), (<值1>, <值2>, ...), ...;
# 给所有字段添加数据
insert into <表名> values (<值1>, <值2>, ...);
# 批量添加数据
insert into <表名> values (<值1>, <值2>, ...), (<值1>, <值2>, ...), ...;示例
1
2
3
4
5-- 给指定字段添加数据
insert into tb_user (id, name, age) values (1, '张三', 20);
insert into tb_user values (1, '张三', 20, '男');
-- 批量添加数据
insert into tb_user (id, name, age) values (1, '张三', 20), (2, '李四', 21), (3, '王五', 22);
1
2# 查看数据
select * from tb_user;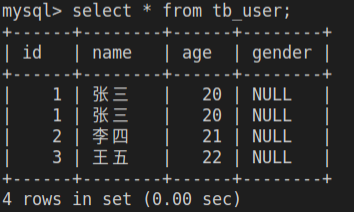
-
注意事项:
- 数据按插入顺序排列
- 日期和字符串等类型需要使用单引号包裹
- 注意字段对应,以及数值范围
-
修改数据
1
2# 修改指定字段的数据
update <表名> set <字段名> = <值> [, <字段名2> = <值2> ...] [where <条件>];示例
1
2
3# 修改指定字段的数据
update tb_user set name = '李四', age = 20 where id = 2;
select * from tb_user;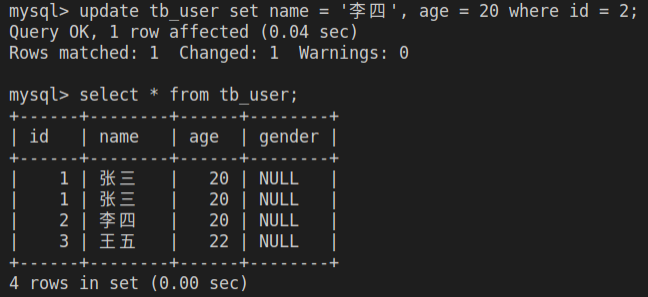
-
删除数据
1
2# 删除指定字段的数据
delete from <表名> [where <条件>];示例
1
2
3# 删除指定字段的数据
delete from tb_user where id = 1;
select * from tb_user;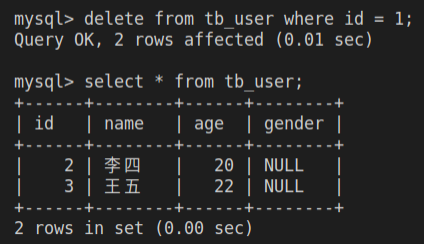
-
总结
1
2
3
4
5
6# 添加数据
insert into <表名> (<字段名1>, <字段名2>, ...) values (<值1>, <值2>, ...);
# 修改数据
update <表名> set <字段名> = <值> [, <字段名2> = <值2> ...] [where <条件>];
# 删除数据
delete from <表名> [where <条件>];
DQL-数据查询语言
数据查询语言(Data Query Language),简称DQL,是用于查询数据的语言(重点!!)
SQL 基本语法
1 | select |
基础查询
-
查询字段
1
2
3
4# 查询所有字段
select * from <表名>;
# 查询指定字段
select <字段名1>, <字段名2>, ... from <表名>; -
设置别名
1
select <字段名1> as <别名1>, <字段名2> as <别名2>, ... from <表名>;
-
去除重复
1
select distinct <字段名1>, <字段名2>, ... from <表名>;
条件查询
-
语法
1
select <字段名1>, <字段名2>, ... from <表名> where <条件>;
-
比较运算
运算符 功能 <, >, >=, <=判断大小 =判断相等 !=或<>判断不相等 between ... and判断在某个范围内(含端点) in(...)判断在之后的列表中 like占位符模糊匹配, _匹配单个字符,%匹配任意个字符is null判断为 NULL -
逻辑运算
运算符 功能 and或&&并且 or或|not或!非 -
示例
1
2
3
4
5
6
7
8
9
10-- 查询年龄小于 22 岁的用户
select * from tb_user where age < 22;
-- 查询年龄在 10 到 20 岁的用户
select * from tb_user where age between 10 and 20;
-- 查找性别非 NULL 的用户
select * from tb_user where not gender is null;
-- 查找姓名长度为 2 的用户
select * from tb_user where name like '__';
-- 查找姓王的用户
select * from tb_user where name like '王%';
聚合函数
-
常见聚合函数
聚合函数 功能 count统计数量 sum求和 avg平均值 max最大值 min最小值 -
语法
1
select <聚合函数>(字段) from <表名> [where <条件>];
-
示例
1
2
3
4-- 查询用户总数(注意 NULL 值会略过)
select count(id) from tb_user;
-- 查询用户最小最大以及平均年龄
select min(age) as young, max(age) as old, avg(age) from tb_user;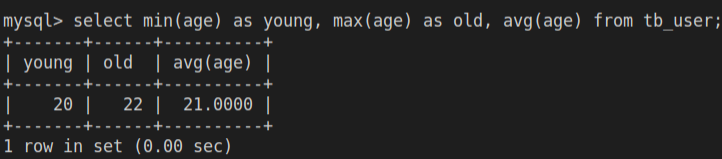
分组查询
-
语法
1
select <字段列表> from <表名> group by <分组字段> [having <分组后的条件>];
-
where和having的区别where在分组之前进行过滤,having在分组之后对结果进行过滤where不能对聚合函数判断,而having可以
-
示例
1
2
3
4
5-- 重新构建数据
truncate tb_user;
insert into tb_user (id, name, age, gender) values (1, '张三', 20, '男'), (2, '李四', 21, '女'), (3, '王五', 22, '男');
-- 按性别分组,统计男女员工的平均年龄
select gender, avg(age), sum(id) from tb_user group by gender;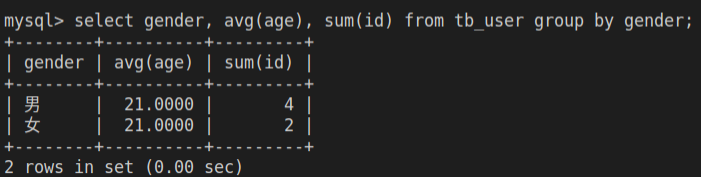
-
示例2
1
2-- 筛选 id < 4,人数大于 1 的性别分类
select gender, count(*) from tb_user where id < 4 group by gender having count(*) > 1;该命令流程:
from tb_user where id < 4筛选id < 4的数据group by gender将数据按gender进行分组having count(*) > 1分组后,进行组内计数,只保留数目大于 1 的情况- 返回分组信息中的字段
gender和count(*)

排序查询和分页查询
-
基础语法
1
2
3
4-- 基本语法
select <字段列表> from <表名> order by <排序字段> [asc|desc];
-- 示例
select * from tb_user order by id desc;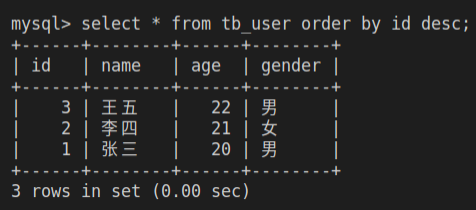
-
多字段排序
1
2-- 多字段排序
select * from tb_user order by id desc, age asc;先按
id排序,id相等的情况按age排序 -
分页查询
1
2
3
4
5
6-- 基本语法
select <字段列表> from <表名> limit <开始位置>, <条数>;
-- 示例 1
select * from tb_user limit 0, 10;
-- 等价写法(开始位置默认值为 0)
select * from tb_user limit 10;
总结
最后,我们用一个示例总结 DQL 查询语句,并解释执行其顺序
-
示例
1
2
3
4-- 基本语法
select <字段列表> from <表名> [where <条件>] [group by <字段>] [order by <排序字段> [asc|desc]] [limit <开始位置>, <条数>];
-- 示例
select gender, count(*) as num from tb_user where id < 10 group by gender having avg(age) > 10 order by num desc limit 10; -
实际执行过程:
from tb_user导入字段数据where id < 10筛选id小于 10 的数据group by gender将数据按gender分组select gender, count(*) as num...提取相应字段的数据having avg(age) > 10筛选平均年龄大于 10 的组order by num desc将数据按num字段降序limit 10限制输出数目为10
DCL-数据控制语言
用来创建数据库用户,控制数据库访问权限等。
管理用户
-
查询用户
1
2
3
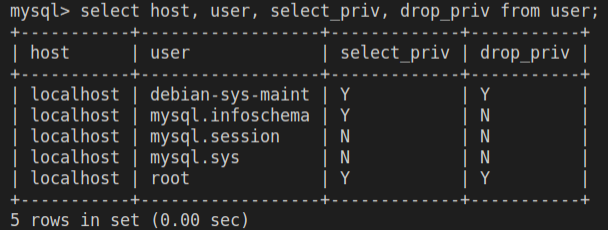
4-- 切换到 mysql 数据库
use mysql
-- 查询用户列表和指定权限
select host, user, select_priv, drop_priv from user;列表中,
host代表允许用户操作的主机地址,user为用户名,select_priv为查询权限,drop_priv为删除权限
-
创建用户
1
2
3-- 创建用户
create user 'rex'@'localhost' identified by '123456';
select host, user, select_priv, drop_priv from user;用户名为
rex,允许操作地址为localhost,密码为123456。初始化后,用户所有权限均为N -
用模糊匹配创建用户,注意
%需要必须在引号中1
create user 'zong'@'%' identified by '123456';
-
修改用户密码
1
alter user 'rex'@'localhost' identified with mysql_native_password by '1234';
-
登录用户,并查看当前的数据库
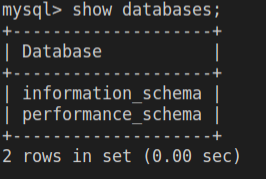
1
2mysql -u rex -p -- 输入1234
show databases;由于缺少权限,用户不能看到数据库
mysql, sys以及刚创建的rextest
-
删除用户
1
drop user 'rex'@'localhost';
权限控制
-
常用权限
权限名称 描述 all, all privileges所有权限 select查询数据 insert插入数据 update更新数据 delete删除数据 create创建数据库/表 drop删除数据库/表/视图 alter修改表 -
查看权限
1
show grants for 'rex'@'localhost';
-
赋予权限,注意只有
root用户能够执行该操作1
2
3
4-- 基础语法
grant <权限列表> on <数据库名>.<表名> to 'rex'@'localhost';
-- 赋予所有权限
grant all on *.* to 'rex'@'localhost';数据库名和表名可以使用
*来匹配所有数据库和表 -
撤销权限,只有
root用户能够执行该操作1
revoke <权限列表> on <数据库名>.<表名> from 'rex'@'localhost';
总结
-
用户管理
1
2
3
4
5
6-- 创建用户
create user 'rex'@'%' identified by '123456';
-- 修改用户密码
alter user 'rex'@'%' identified with mysql_native_password by '1234';
-- 删除用户
drop user 'rex'@'%'; -
权限管理(赋予,撤销仅 root 用户可以操作)
1
2
3
4-- 赋予权限
grant <权限列表> on <数据库名>.<表名> to 'rex'@'localhost';
-- 撤销权限
revoke <权限列表> on <数据库名>.<表名> from 'rex'@'localhost';
函数
-
常见字符串函数列表
| 函数名称 | 描述 |
| ---------- | ---- |
|concat(s1, s2, ...)| 将多个字符串连接起来 |
|lower(str)| 将字符串转换为小写 |
|upper(str)| 将字符串转换为大写 |
|lapd(str, n, pad)| 在字符串左侧填充字符pad,使得长度为 n |
|rpad(str, n, pad)| 在字符串右侧填充字符pad,使得长度为 n |
|trim(str)| 去除字符串两端的空白字符 |
|substring(str, start, length)| 截取字符串的子串 | -
示例-字符串函数
1
2-- 字符串连接,字符串转化小写
select concat('hello', ' mysql'), lower("HELLO MYSQL");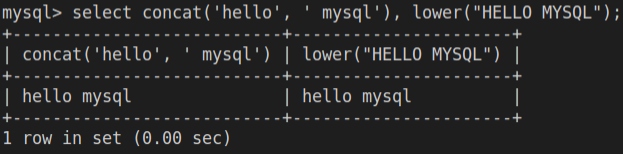
-
将函数用于更新列表
1
2
3
4-- 切换到 `rextest` 数据库
use rextest;
-- 更新列表
update tb_user set name = concat('hello', name);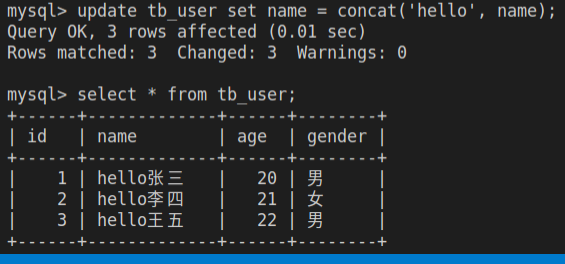
-
常见数值函数列表
函数名称 描述 ceil(x)向上取整 floor(x)向下取整 round(x, y)四舍五入,保留 y位小数rand()0~1 的随机数 mod(x, y)返回 x 和 y 的余数 power(x, y)返回 x 的 y 次幂 -
常见日期函数列表
函数名称 描述 curdate()返回当前日期 curtime()返回当前时间 now()返回当前日期和时间 year(date)返回日期的年份 month(date)返回日期的月份 day(date)返回日期的天 date_add(date, interval)在日期上增加时间间隔 datadiff(date1, date2)返回两个日期之间的天数 -
示例
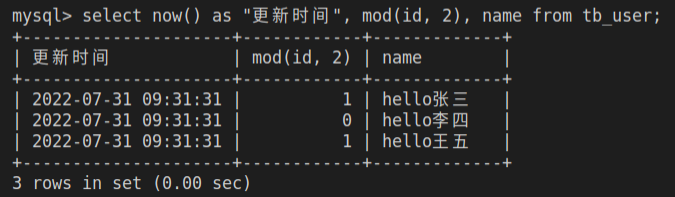
1
select now() as "更新时间", mod(id, 2), name from tb_user;
-
流程函数列表
函数名称 描述 if(condition, t, f)如果条件为真,则返回 t,否则返回fifnull(x, y)如果 x 为空,则返回 y case [expr] when [val1] then [res1] else [default] end当 expr 等于 val1 时返回 res1,否则返回 default -
示例
1
2
3
4-- id 为 1,返回 `yes`,否则返回 `no`
select name, if(id = 1, 'yes', 'no') as "是否为第一个用户" from tb_user;
-- 判断条件
select name, (case when id = 1 then 'first' when id = 2 then 'second' else 'greater than 2' end) as "用户 ID 序数" from tb_user;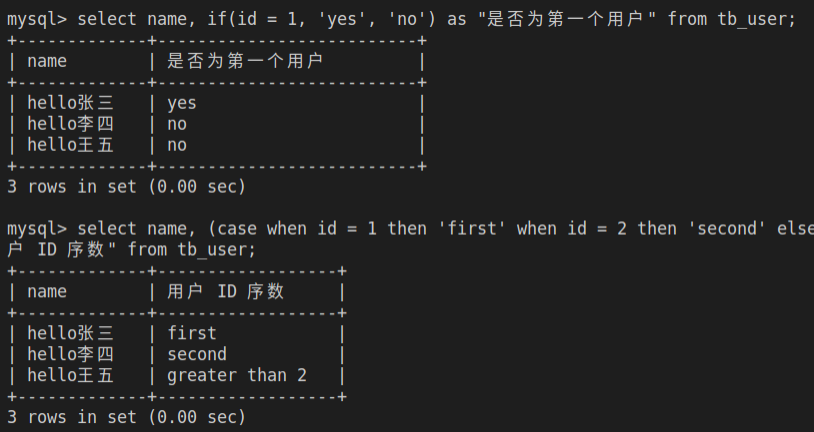
约束
多表查询
事务
进阶,运维。
SPARQL
参考链接:B 站视频:知识库 vs 数据库,官方文档
wikidata 知识库支持 SPARQL 查询语法,访问链接:https://query.wikidata.org/
简单概括:数据库是由关系表构成的,格式固定的存储结构,而知识库是通过三元组搭建的图结构,
基本用法
-
示例
1
2
3
4
5
6
7# 猫
SELECT ?item ?itemLabel
WHERE
{
?item wdt:P31 wd:Q146. # 必须是一只猫
SERVICE wikibase:label { bd:serviceParam wikibase:language "zh". }
} -
说明-和 SQL 的语法类似,
select提取数据,where限定规则?item定义变量名为item?itemLabel在变量名后追加Label,代表item的Label标签?item wdt:P31 wd:Q146.定义查询条件,wdt:P31是instance of的简写,wd:Q146是house cat的简写- 具体地,可以在词条中查看到性质
instance of的简写是P31
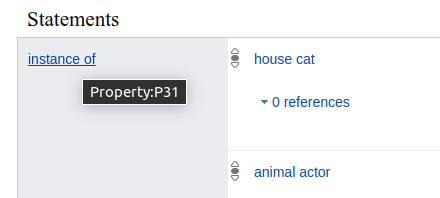
- 类似地,
house cat的简写为Q146
- 最后一行代码定义
label的语言
API
 wechat
wechat alipay
alipay